
client-go原理
本文主要讲解kubernetes的调用过程,以及kubernetes的api设计。
client-go原理
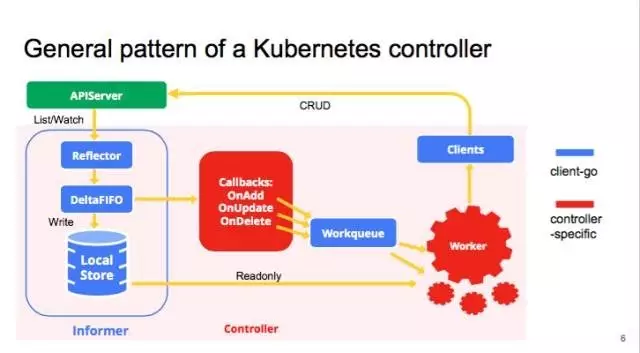
- Controller 使用 informer 来 list/watch apiserver,然后将资源存储于本地的 cache 中。
- 如果 informer 监听到了资源的变化(创建/更新/删除),就会调用事先注册的ResourceEventHandler 回调函数。
- 在 ResourceEventHandler 回调函数中,其实只是做了一些很简单的过滤,然后将关心变更的 Object 放到 workqueue 里面。
- Controller 从 workqueue 里面取出 Object,启动一个 worker 来执行自己的业务逻辑,业务逻辑通常是计算目前集群的状态和用户希望达到的状态有多大的区别,然后孜孜不倦地让 apiserver 将状态演化到用户希望达到的状态,比如为 deployment 创建新的 pods,或者是扩容/缩容 deployment。
- 在worker中就可以使用 lister 来获取 resource,而不用频繁的访问 apiserver,因为 apiserver 中 resource 的变更都会反映到本地的 cache 中。
clients
Clientset
Clientset 是我们最常用的 client,你可以在它里面找到 kubernetes 目前所有原生资源对应的 client。 获取方式一般是,指定 group 然后指定特定的 version,然后根据 resource 名字来获取到对应的 client。
Dynamic Client
Dynamic client 是一种动态的 client,它能同时处理 kubernetes 所有的资源。并且同时,它也不同于 clientset,dynamic client 返回的对象是一个 map[string]interface{},如果一个 controller 中需要控制所有的 API,可以使用dynamic client,目前它被用在了 garbage collector 和 namespace controller。
RESTClient
RESTClient 是 clientset 和 dynamic client 的基础,前面这两个 client 本质上都是RESTClient,它提供了一些 RESTful 的函数如 Get(),Put(),Post(),Delete()。由 Codec 来提供序列化和反序列化的功能。
如何选择 Client 的类型呢?
如果你的 Controller 只是需要控制 Kubernetes 原生的资源,如 Pods,Nodes,Deployments等,那么 clientset 就够用了。
如果你需要使用 crd 来拓展 Kubernetes 的 API,那么需要使用 Dynamic Client 或 RESTClient。
需要注意的是,Dynamic Client 目前只支持 JSON 的序列化和反序列化。
常用组件介绍
Informer
最佳实践
- 等待所有的 cache 同步完成: 这是为了避免生成大量无用的资源,比如 replica set controller 需要watch replica sets 和 pods, 在 cache 还没有同步完之前,controller 可能为一个 replica set 创建了大量重复的 pods,因为这个时候 controller 觉得目前还没有任何的 pods。
- 修改 resource 对象前先 deepcopy 一份: 在 Informer 这个模型中,我们的 resource 一般是从本地 cache 中取出的,而本地的 cache 对于用户来说应该是 read-only 的,因为它可能是与其他的 informer 共享的,如果你直接修改 cache 中的对象,可能会引起读写的竞争。
- 处理 DeletedFinalStateUnknown 类型对象: 当你的收到一个删除事件时,这个对象有可能不是你想要的类型,即它可能是一个 DeletedFinalStateUnknown,你需要单独处理它。
- 注意 informer 的 resync 行为, informer 会定期从 apiserver resync 资源,这时候会收到大量重复的更新事件,这个事件有一个特点就是更新的 Object 的 ResourceVersion是一样的,将这种不必要的更新过滤掉。
- 在创建事件中注意 Object 已经被删除的情况: 在 Controller 重启的过程中,可能会有一些对象被删除了,重启后,Controller 会收到这些已删除对象的创建事件,请把这些对象正确地删除。
- SharedInformer: 建议使用 SharedInformer, 它会在多个 Informer 中共享一个本地 cache,这里有一 个 factory 来方便你编写一个新的 Informer。
简化informer构建
在 client-go 中提供了一个 SharedInformerFactory 来简化 informer 的构建,具体代码在:factory.go
Lister
Lister 是用来帮助我们访问本地 cache 的一个组件。
Workqueue
Workqueue 是一个简单的 queue 提供了以下的特性:
- 公平性:每个item 按顺序处理。
- 严格性:一个 item 不会被并发地多次处理,而且一个相同的 item 被多次加入 queue 的话也只会处理一次。
- 支持多个生产者和消费者:它允许一个正在被处理的 item 再次加入队列。
我们建议使用 RateLimitingQueue,它相比普通的 workqueue 多了以下的功能:
- 限流:可以限制一个 item 被 reenqueued 的次数。
- 防止 hot loop:它保证了一个 item 被 reenqueued 后,不会马上被处理。
Workqueue helper:
这里有一个 workqueue 的封装,来简化 queue 的操作,代码在以下位置:helper.go
控制流总结
我们来总结一个控制器的整体工作流程。
- 创建一个控制器
- 为控制器创建 workqueue
- 创建 informer, 为 informer 添加 callback 函数,创建 lister
- 启动控制器
- 启动 informer
- 等待本地 cache sync 完成后, 启动 workers
- 当收到变更事件后,执行 callback
- 等待事件触发
- 从事件中获取变更的 Object
- 做一些必要的检查
- 生成 object key,一般是 namespace/name 的形式
- 将 key 放入 workqueue 中
- worker loop
- 等待从 workqueue 中获取到 item,一般为 object key
- 用 object key 通过 lister 从本地 cache 中获取到真正的 object 对象
- 做一些检查
- 执行真正的业务逻辑
- 处理下一个 item 到这里已经讲完了一个完整的 Kubernetes 的 Controller 的构建过程。但是还想要多啰嗦几句关于 kubernetes 的设计原则和 API 习俗,它们是指导我们写出更加可靠的 Controller 的白皮书。
设计原则
- 功能设计基于 level_based,这意味系统应该在给定的 desired state 和 current/observed state 情况下也能正确运行,不管这中间有多少更新的信息被丢失了。Edge-triggered 只能用来进行优化(应该有一个类似于 CAP 的理论去指导我们权衡应该轮询还是使用事件驱动的方式去控制我们的流程,在高性能,可靠性和简单些三者之间选其二)。
- 假定我们的系统是一个开放的环境:应该不断的去验证系统假设,优雅地接受外部的事件和修改。比如用户可以随意地删除正在被 replica set 管理的 pods,而 replica set 发现了之后只是简单的重新创建一个新的pod 而已。
- 不要为 object 建立大而全的状态机,从而把系统的行为和状态机的变迁关联起来。
- 不要假设所有的组件都能正常运行,任何组件都有可能出错或者拒绝你的请求。etcd 可能会拒绝写入,kubelet 可能会拒绝 pod, scheduler 可能会拒绝调度,尽量进行重试或者有别的解决方案。
- 系统组件能够自愈:比如说 cache 需要定期的进行同步,这样如果有一些 object 被错误的修改或者存储了, 删除的事件被丢失等问题能够在人类发现之前被自动修复。
- 优雅地进行降级和熔断,优先满足最重要的功能而忽略一些无关紧要的小错误。
Kubernetes API 习俗
Spec and status
- Spec 表示系统希望到达的状态,Status 表示系统目前观测到的状态。
- PUT 和 POST 的请求中应该把 Status 段的数据忽略掉,Status 只能由系统组件来修改。
- 有一些对象可能跟 Spec 和 Status 模型相去甚远,可以吧 Spec 改成更加适合的名字。
- 如果对象符合 Spec 和 Status 的标准的话,那么除了 type,object metadata 之外不应该有其他顶级的字段。
- Status 中 phase 已经是 deprecated。因为 pahse 本质上是状态机的枚举类型,它不太符合 Kubernetes 系统设计原则, 并且阻碍系统发展,因为每当你需要往里面加一个新的 pahse 的时候你总是很难做到向后兼容性,建议使用 Condition 来代替。
Primitive types
- 避免使用浮点数,永远不要在 Spec 中使用它们,浮点数不好规范化,在不同的语言和计算机体系结构中有 不同的精度和表示。
- 在 JavaScript 和其他的一部分语言中,所有的数字都会被转换成 float,所以数字超过了一定的大小最好使 用 string。
- 不要使用 unsigned integers,因为不同的语言和库对它的支持不一样。
- 不要使用枚举类型,建立一个 string 的别名类型。
- API 中所有的 integer 都必须明确使用 Go(int32, int64), 不要使用 int,在32位和64位的操作系统中他们的位数不一样。
- 谨慎地使用 bool 类型的字段,很多时候刚开始做 API 的时候是 true or false,但是随着系统的扩张,它可能 有多个可选值,多为未来打算。
- 对于可选的字段,使用指针来表示,比如 *string *int32 , 这样就可以用 nil 来判断这个值是否设置了, 因为 Go 语言中string int 这些类型都有零值,你无法判断他们是没被设置还是被设置了零值。
总结
为 Kubernetes 拓展一个功能,实现一个 controller 是简单的。
但是设计一个系统,抽象出其中的设计哲学,更加值得我们学习和深思。
下面这个项目可以视为 controller 的一个例子: loadbalancer-controller
